Vehicle Damage Detection System
Building an AI-assisted vehicle inspection system that combines computer vision with structured decision workflows to support scalable insurance assessment processes.
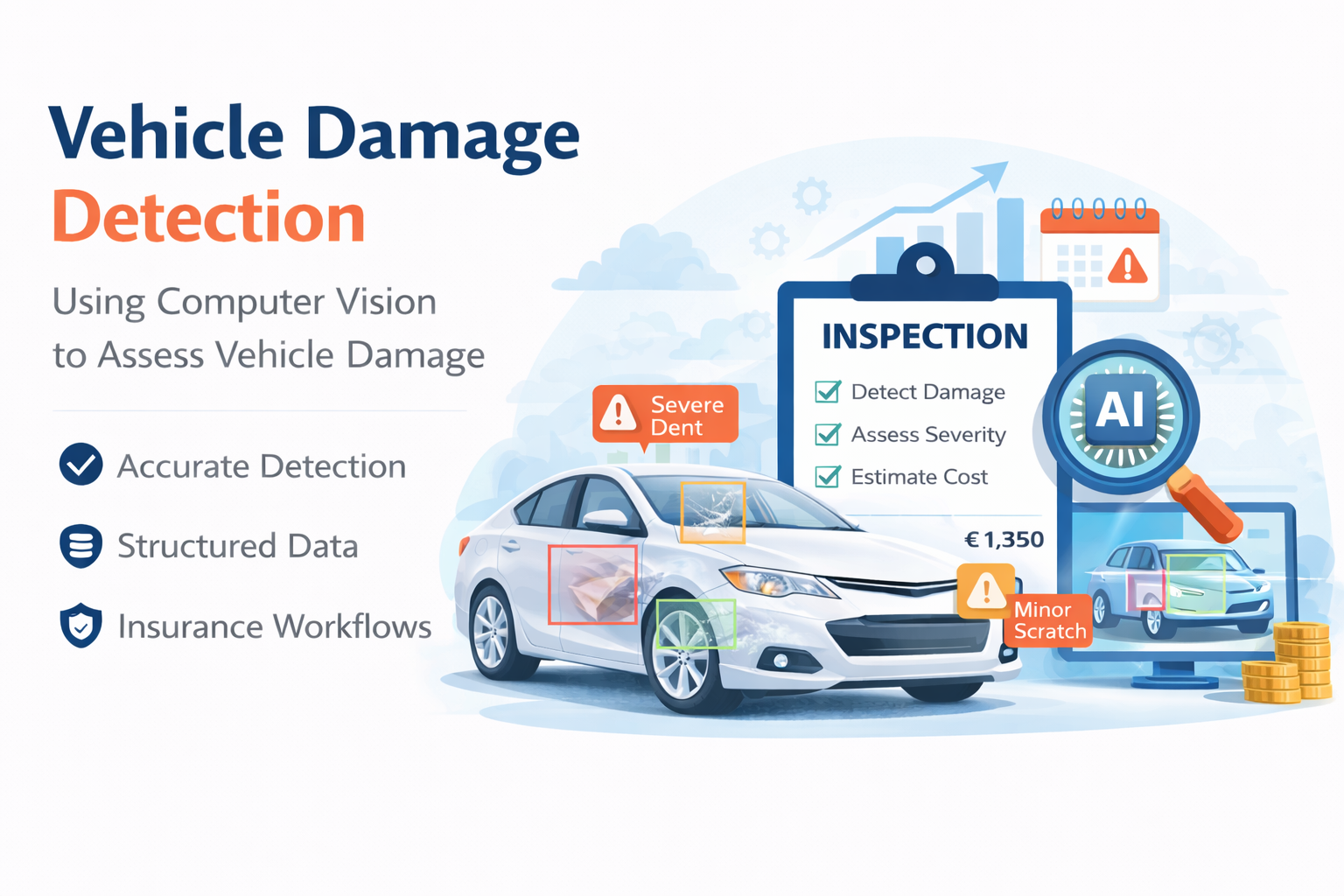
Why This Project?
Vehicle damage assessment is often manual, time-consuming, and highly dependent on human inspection. These processes can slow down claims handling and introduce inconsistencies across insurance workflows.
This project explores how AI can automate parts of this process and create more scalable and data-driven approaches to vehicle assessment.
Project Vision
Rather than building a standalone detection model, the objective is to develop an intelligent inspection pipeline that gradually moves from image understanding toward decision support.
The long-term goal is to bridge computer vision with practical insurance workflows and build systems that can support future automation initiatives.
System Architecture
The project follows a modular pipeline where each component can evolve independently while remaining connected through a common workflow.
- Detection → Identify damage types and their locations
- Assessment → Interpret damage severity
- Risk Estimation → Generate simple cost or risk insights
Engineering Approach
The system is being designed with extensibility in mind rather than as a single deep learning model.
- Modular architecture with independently evolving components
- API-first design for future integrations
- Structured outputs for downstream applications
- Extensible pipeline for additional AI capabilities
Future Roadmap
This project will gradually evolve into a more complete intelligent inspection platform.
- Improve multi-damage detection performance
- Build structured severity scoring systems
- Enhance risk estimation workflows
- Generate AI-assisted inspection summaries